
今回は、img2img (画像から画像を生成)の使い方を一緒に学んでいきたいと思います。
以前 txt2img と同じように、各パーツの説明で行きたいと思います。
img2img でできること
基本 img2img は以下のことができると思います。
※ まだ使ったことある機能もあるかもしれませんが、今後知ったら追加する予定です。
- 画像をベースに、似たような画像を生成する
- 画像の一部を修正(追加、削除、変更など)
ちょっと文字が小さいかもしれませんが、img2img のタブ内容はこのようになっています。

では、各部分を見ていきましょう
txt2img と共同の部分
以下の項目については、基本 txt2img と同じものになっていますので、説明を省きます。
詳細は txt2img の記事を見ていただければと思います。

- prompt
- sampling method
- sampling steps
- Restore faces,Tiling
- Width,Height,Batch count,Batch size
- CFG Scale
- seed
- script
img2img - tabs
img2img では、タブごとに機能が用意されています。

- img2img(画像から画像):画像をベースに、新しい画像を生成
- 画像を丸ごと作り直す
- 塗りをベースに作り直すらしい(なので、線だけでは AI がわからないかも)
- sketch(手描き):画像を手描きを加えて再生成する
- 作りなおすに近いので、prompt もがっつり描く必要がある
- img2img と似ているので、元イメージに追加要素を入れてから生成する場合に使うかも
- inpaint(局所塗りなおす):塗りつぶした部分のみを描き直す
- 図の一部の追加、変更、削除などが可能
- inpaint sketch:inpaint と似た感じで、手描きで描いた色に合うような変更を行う
- 色彩ペンで塗ることができる
- AI は色だけを見るので、線画だけ追加しても認識しない可能性がある
- 塗った部分だけ内容が追加される(塗ってない部分は変わらない)
- inpaint upload(マスク画像をアップロード):別途で用意した白(編集したい範囲)黒(編集しない範囲)のファイルをアップロードして、高い精度で範囲を特定できるモード
- photoshop などと併用することが多い
- batch:複数画像を同じ方法で処理させたい場合利用する
img2img - 共通パーツ
prompt

- 画像から要素の単語や文言を生成する(Interrogate:尋問する)
- Interrogate CLIP:文言で表現する
- Interrogate DeepBooru:単語で表現する(個人的にお勧め)
copy image to
アップロードしたイメージや、sketch したイメージを直接他のタブに移動するときに使います。

resize mode
アップロードする画像と生成される画像のサイズが違う場合、サイズの差をどう埋めていくかの方法の指定です。

- Just resize(拉伸):縦横比例を無視して、無理やり画像を伸ばして(縮めて)、生成する画像のサイズの合わせる
- 元画像と生成画像の縦横比例が違う場合、キャラの頭が伸びたり変になるかも

- 元画像と生成画像の縦横比例が違う場合、キャラの頭が伸びたり変になるかも
- crop and resize(裁剪):縦横比例を維持しながら、はみ出る部分をカットされる
- 縦、横の小さいほうを基準に画像を生成、はみ出た部分をカットする

- 縦、横の小さいほうを基準に画像を生成、はみ出た部分をカットする
- resize and fill(填充):縦横比例を維持しながら、不足の部分を追加してくれる
- 縦、横の大きいほうを基準に画像を生成、余白の部分は入れてくれる

- 縦、横の大きいほうを基準に画像を生成、余白の部分は入れてくれる
- just resize (latent upscale):Just resize に似てるが、AI が処理してくれるので、少しランダム要素が増える
- 望むような結果がめったに出ないので、あんまり使わないかも?

- 望むような結果がめったに出ないので、あんまり使わないかも?
Denoising strength (ノイズ除去強度)
Denoising strength は、元の画像の影響がどのぐらい残すかの設定です。
数値が大きいほど、元の画像の影響が小さくなります。(別画像になる)
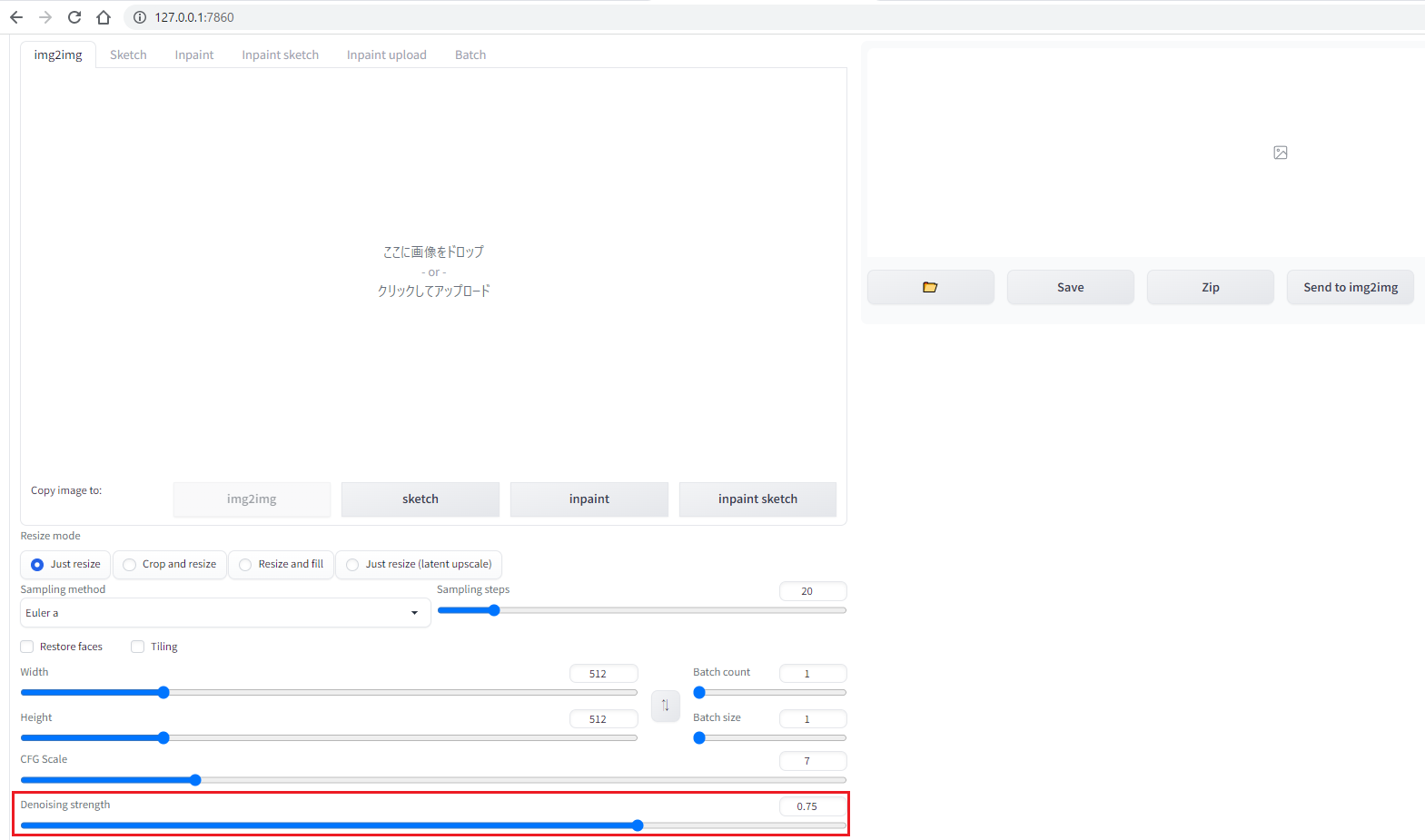
- 値大きいほど、元の画像から離れてします(prompt が効いてくる)
- 大き過ぎると、全く別物になるので、あんまり意味ないかも
- 値小さいほど、元の画像のままに近い
- 小さ過ぎると、ほぼ同じ画像になるので無意味かも
なので、大体 4.5 ~ 7.5 の間を使われることが多いらしいです。
inpaint - Mask
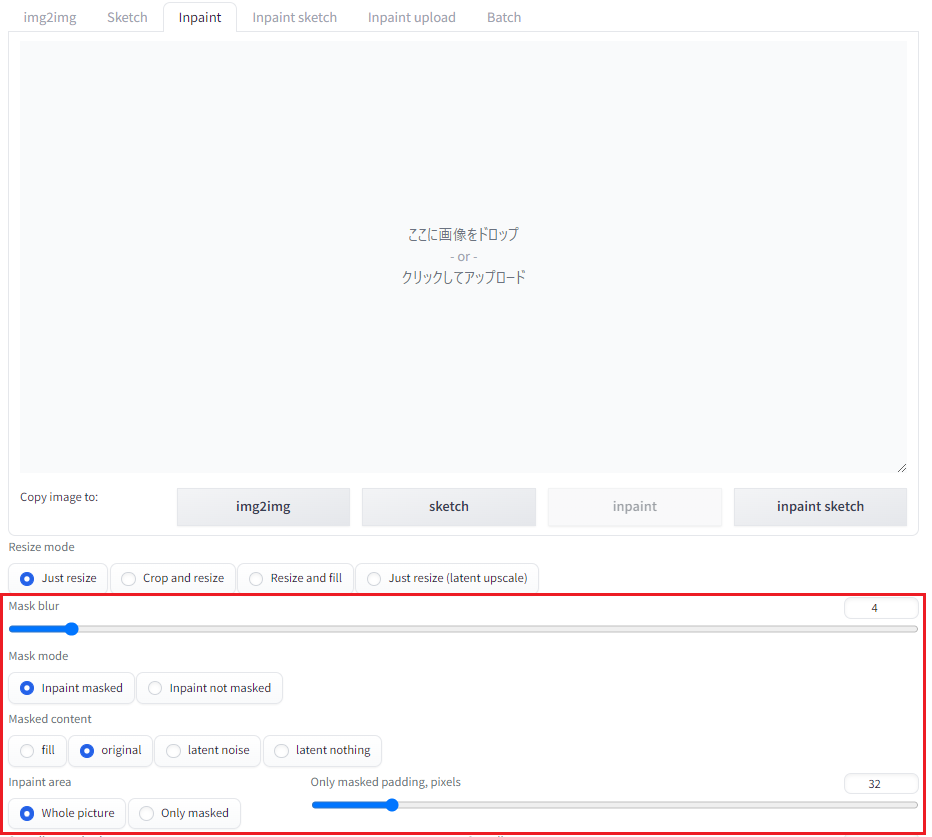
Mask 機能を使うことで、いろんなことができますが、例えば以下のものです。
- もの置き換え
- キャラの服装、飾りの変更
- 間違った部分の修正
- いらないのもの削除
- etc.
マスク ペン
まずは、マスクのつけ方になります。
画像をアップロードしたら、画像エリアの右上に、撤回、削除、ペンの3つのマークが表示されます。

ペンを選択して、塗りつぶした部分がマスク部分になります。塗り間違った場合、撤回ボタンで1ステップ前に戻すことができます。
Mask mode
- inpaint masked:塗りつぶした部分を描きなおす
- inpaint not masked:塗りつぶしていない部分を描きなおす
Mask blur(ぼかし)
マスク部分の境界線のぼかし設定です。
inpaint はマスク部分のみ描きなおすので、マスク部分以外の部分との接続境界がおかしいことになる可能性があるので、この境界をぼかすための設定です。
- 数値が小さいほど、境界線がはっきり見える
- photoshop のぼかし機能と似ているかも
- デフォルト値の 4 で基本大丈夫
- 境界線が気になるようであれば、他の値を試してみるのもよし
Masked content
AI 処理するとき、(色彩の)処理傾向を決める設定値です。
- fill:背景の色(コンテンツ)で、マスクした部分を描きなおす
- 元画像の何かを削除することでよく利用する
- original:色彩の処理が元画像の色分布と一致する
- 元々画像に存在する色ブロックが消えることないが、別のものに変えることができる
- latent noise:選択した部分は元画像を参考せずに、ランダムで(AI の想像力)描きなおす
- fill みたいに、背景色を参考に修正
- 色彩のランダムの幅が広い:誇張する表現になる
- アイディアを生み出すのによく使うかも
- lantent nothing:選択した部分は元画像を参考せずに、ランダムで(AI の想像力)描きなおす
- fill みたいに、背景色を参考に修正
- 色彩のランダムの幅が小さい:そんなに変わらない
- 少しだけ違いを見せたい場合使うかも
inpaint area
inpaint area:prompt、属性、モデルが影響する範囲を指定します。
inpaint は選択した部分のみ変更されますが、ただ AI は whole picture を見て生成するのか、選択した部分のみを見て生成するのかによって、生成された結果が異なります。
- whole picture:prompt、属性、モデルは図全体に効いて、その上でマスク部分を修正する
- 画像全体を見ているので、追加したいものが思い通り追加されない場合がある
- only masked:prompt、属性、モデルはマスクした部分のみ適用する
- 例えば、マスクして、Prompt に
1ballを入れると、ボールが追加される - 特定のものを追加したい場合よく利用する
- only masked padding,pixels:マスクの部分のみではなく、指定の pixels まで拡張して適用する
- only masked の追加設定
- 例えば、マスクして、Prompt に
only masked 例:

AI が作画するので望ましい結果が出ない場合、色々試してみたほうがよいでしょう。

コメント