
前回は Stable diffusion の導入方法について勉強しました。
今回から正式に使ってみていきたいと思います。
今回は txt2img(テキストから画像生成)の使い方から勉強して行きましょう。
Stable diffusion の起動
stable-diffusion-webuiのディレクトリに移動します。stable-diffusion-webui/webui-user.batを実行します。- linux OS の場合
stable-diffusion-webui\webui-user.shで起動します。
- linux OS の場合
- コマンド プロンプトが立ち上がり、ダウンロードが開始されます。
- 10 GB ほどダウンロードするので、少し時間かかります。
- コマンド プロンプトの出力に
Running on Local URL: http://127.0.0.1:xxxxのような出力が表示されたら、起動完了です。 http://127.0.0.1:xxxxをコピーして、ブラウザでアクセスします。- コマンドプロンプトは閉じないでください。
stable-diffusion-webuiの以下画面が表示されたら、起動完了です。
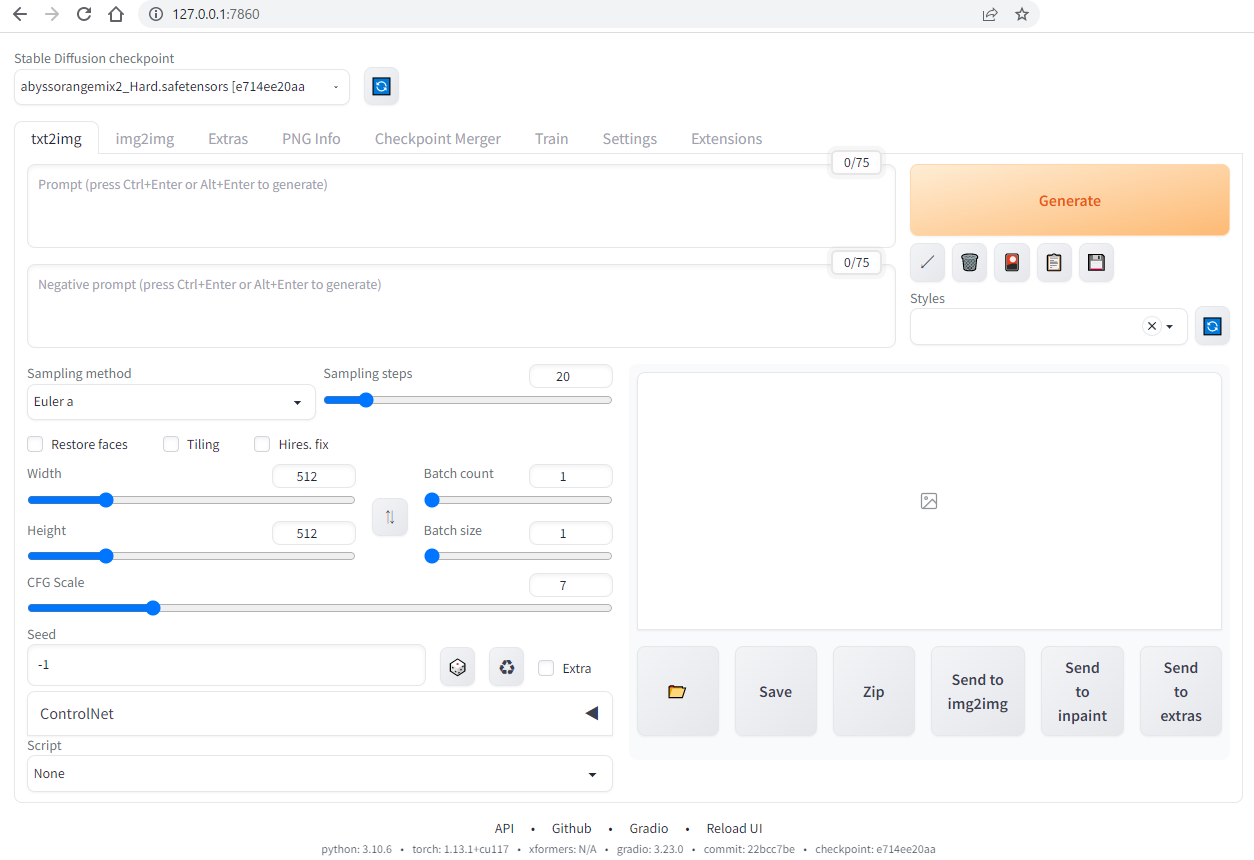
各パーツの説明
イラストの model
一般的には CIVITAI で無料で他の人がシェアしたモデル (checkpoint) をダウンロードできます。
ダウンロードしたモデルを /stable-diffusion-webui/models/Stable-diffusion フォルダに配置すると、stable-diffusion-webui で利用できるようになります。
導入したモデルは以下のところで指定して使用します。
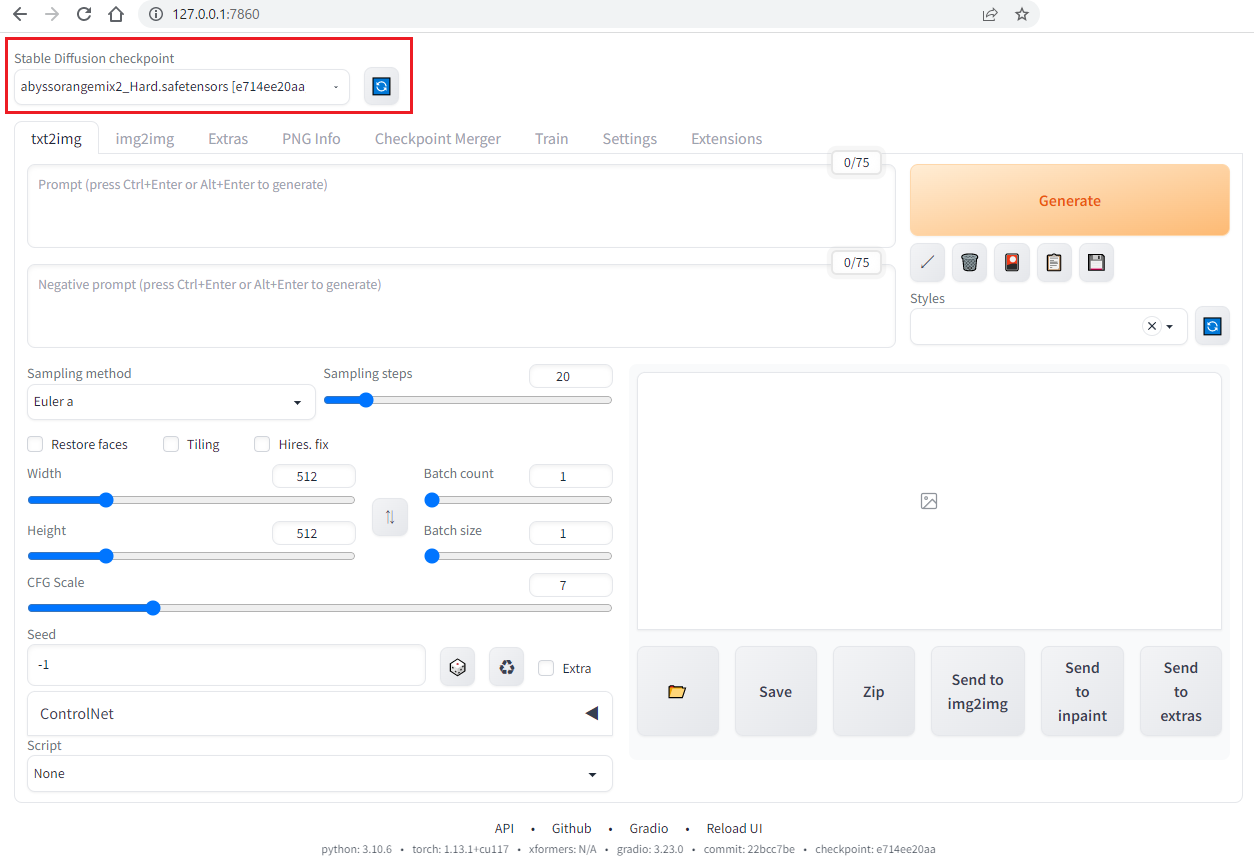
タブ
Stable diffusion にはいろんな機能が備わっています。
機能それぞれ違うタブで分かれています。

- txt2img:テキストで画像を生成します。
- img2img:画像から画像を生成します。
- EXtras:画像を拡大します。
- 後ほど紹介する Hires.fix と大体同じ役割だが、画像生成と別れているため、が GPU リソース的なメリットがあるかも
- PNG Info:Stable diffusionで生成された原本から、テキスト情報を引き出します。
- checkpoint Merger:二つのモデルをマージします。
- Train:モデルのトレーニング(上級者向け、一般的な利用者は気にしなくても大丈夫です)
- Settings:Stable diffusion の設定を弄るところです。
- Extensions:Stable diffusion の拡張機能のインストール&管理するところです。
今回は txt2img を中心に使い方を紹介しますので、以下の部分は txt2img の部分のパーツの説明をします。
txt2img - prompt
txt2img の prompt 部分はテキストを入力する部分になります。
上段は prompt で、下段は negative prompt になります。
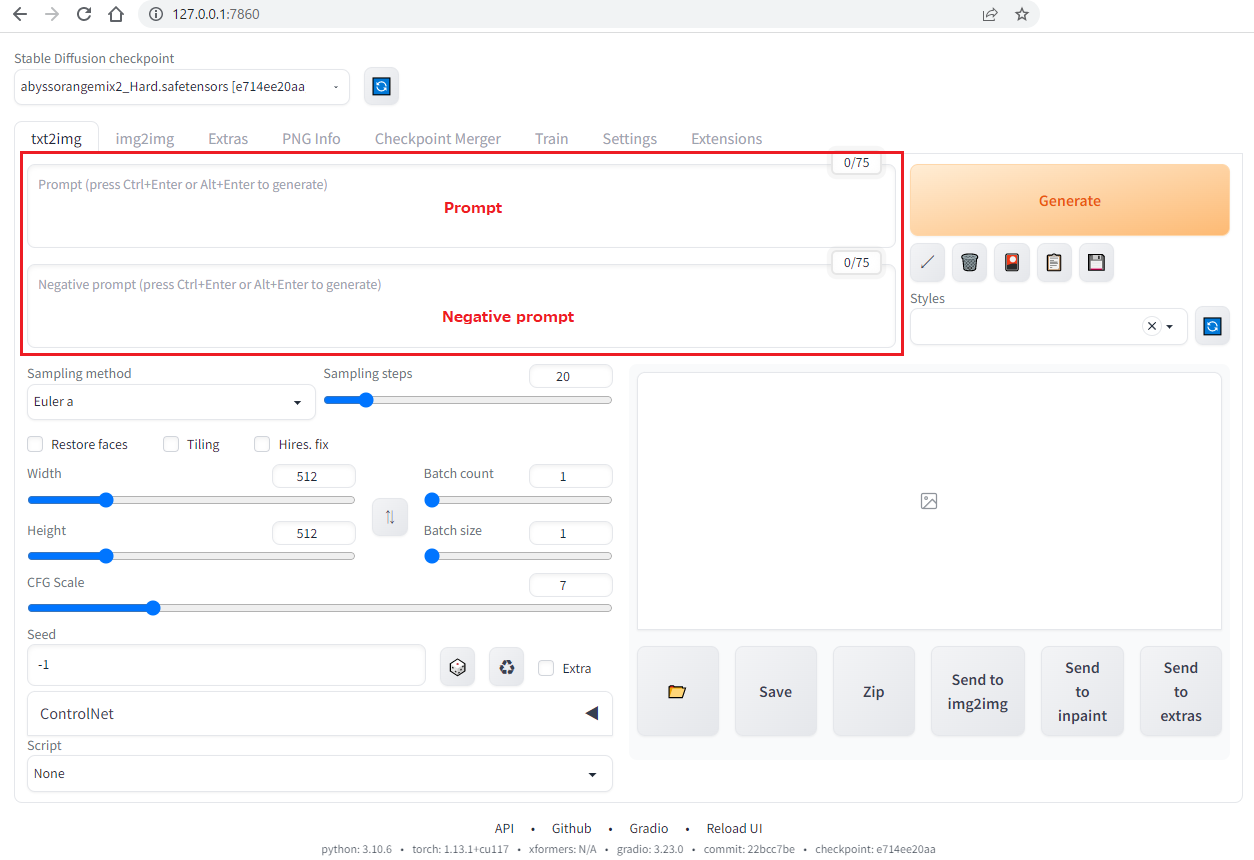
- prompt:書いてほしい画像の要素を書きます。
- negative prompt:書いてほしくない要素を書きます。
複数要素を同時に書くこともできますが、要素の間は , で分割します。
prompt 例:
(best quality, masterpiece:1.2), 1girl,skirt,white long hair,nice face,pink eyes,red eye shadow,saliva trail,large_breasts ,forest,looking down on viewer, negative prompt 例:
(worst quality, low quality:1.2), 一旦ここまで書けば「Generate」ボタンで画像を生成することができます。
prompt の文法と特性
特性:
- 要素を先頭に書くほど、影響が大きい(優先度高)です
- 一般的に以下の部分で要素を書きます
- 品質に関する要素
- 例:
masterpiece, best quality, ultra detailed, - 品質に関する要素は Negativate prompt でも効果がある
- 例:
(worst quality, low quality:1.2),
- 例:
- 作風に関する要素
- 例:
anime,,oil painting,Pablo Picasso(有名な画家の名前) - 環境に関する要素:構図の情報、時間帯、季節、天候など
- 例:
full body, portrait, winter, snowfall, japan, Sengoku period, looking down on viewer - 主体を描写する要素:性別、服装、ポーズ、表情など
- 例:
1girl,skirt,white long hair,nice face,pink eyes,red eye shadow, lying on bed
文法:
():中の要素の影響度を 1.1 倍にする- 多重使用可能で、囲むごとで、1.1 倍で乗算される
((要素))は 1.21 倍- 括弧の中に複数要素を入れることが可能
(worst quality, low quality:1.2),
(要素:1.3):指定倍数の影響度を与える- 1.5 を超える数値を使用し内容がいい
[]:中の要素の影響度を 1.1 で割る(0.91 倍になる)- その他の特徴は
()と同じ
- その他の特徴は
Stable diffusion img2img で生成した例
- 単語の間に
_が入る ,の後ろにスペース一つ入る- 一部強調の場合
\(単語\)で記述\(単語\)はエスケープ(python)かと思われる
1girl, bangs, bare_shoulders, blue_eyes, blush, bow, breasts, cleavage, collarbone, eyebrows_visible_through_hair, flower, green_hair, hair_flower, hair_ornament, hairband, hand_up, japanese_clothes, kimono, large_breasts, light_particles, lily_\(flower\), long_hair, long_sleeves, looking_at_viewer, night, night_sky, obi, off_shoulder, parted_lips, red_bow, sash, sidelocks, sky, smile, snowing, solo, star_\(sky\), starry_sky, sweat, thighs, very_long_hair, wet, white_flower, white_kimono, white_rose,※ あんまりいいアイディアがない時、生成したそれなりのいい絵で、img2img で要素単語を生成させるのもありかもしれませんね。
txt2img - sampling method
sampling method によって出てきた画風が結構違ってきます。
一般的にイラストを生成するなら Karras がついているものが人気らしいです。
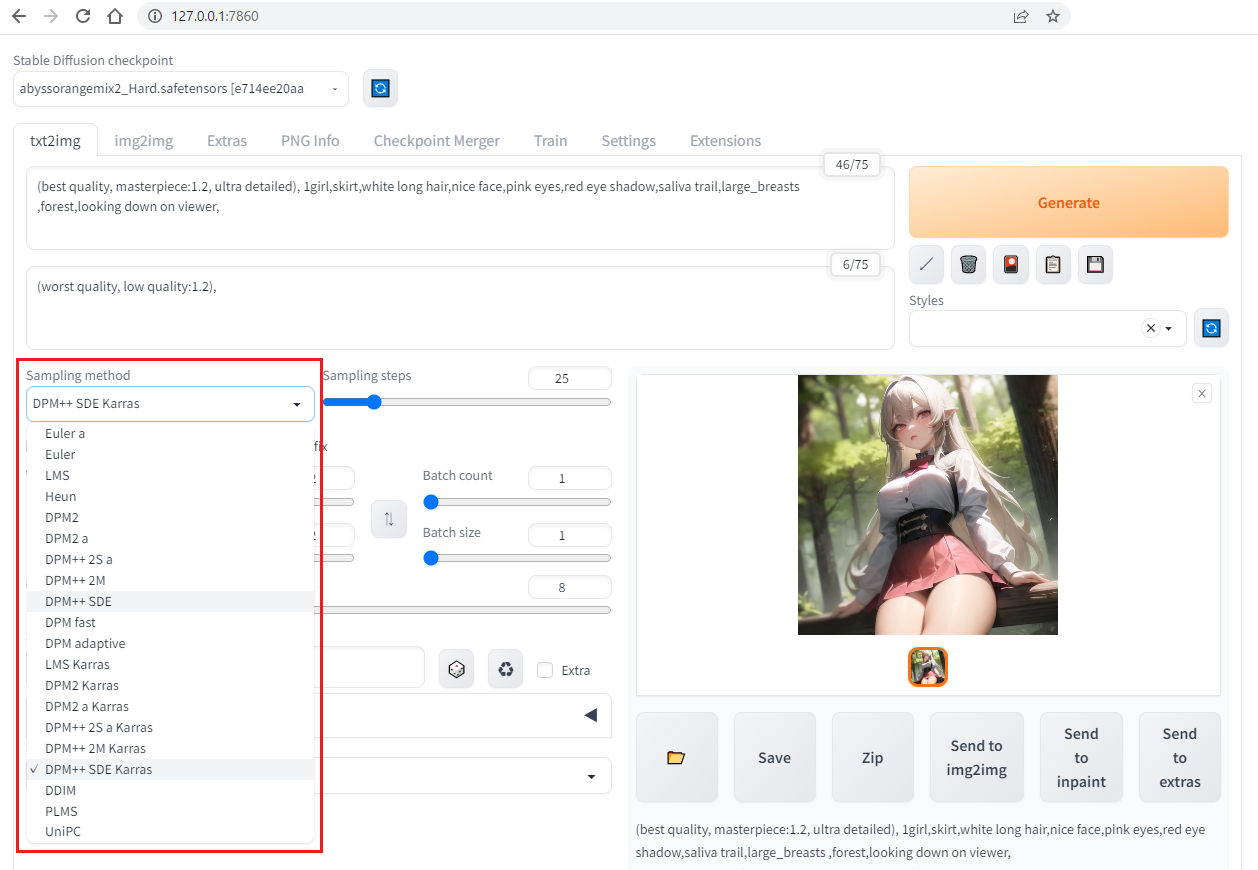
txt2img - sampling steps
sampling steps を大きくすると detail が増しますが、生成の時間が長くなります。しかも40以上にした場合、あんまり変わらなくなりますので、20 ~ 40 がいいといわれています。

txt2img - Restore faces,Tiling

- Restore faces(顔修正):リアル風な人の顔修正に使用可能
- 2次元キャラに使うと変になりがち
- Tiling:人物には使いません
- Hires.fix:アップスケーラー(画像をアップスケール)として機能する
Hires.fix
小さい画像をスケールアップする機能です。(裏では img2img でやってるらしい)
- upscaler:画像拡大するアルゴリズム(方法)
- Latent (nearest):元の絵柄のまま、細部の描き込みを増やす特徴
- Latent は SD の潜在空間を使った拡大(img2img による拡大)
- Latent は元画像にないものまで描ける → まったく別の画像にもなるかも
- その他:画像拡大アルゴリズム(下にあるほど新しい?)
- Hires steps:i2iする時のstepsです。
- デフォルトは 0 になっていて、元の sampling steps が適用されます
- 15 で十分らしい? sampling steps の 1/4 がいいという話も?(画像ごとに色々試した方がいいかも)
- Denoising strength:i2iする時のノイズ除去の値
- 小さい数値は元画像に近く、大きい数値にする程描き直しになります
- 0.6 以内なら元の画像に近い状態を保てる感じがします
- hires.fix は i2i で処理しているらしい
- Upscale by:拡大の倍率(~ 4倍まで可能)
- 2 前後がいいでしょう
- Resize width to:width サイズ変更
- Resize height to:height サイズ変更
※ 拡大するほど、生成に時間がかかります。
txt2img - Width,Height,Batch count,Batch size,CFG Scale

- width,Hight:画像の解像度、大きくすると生成に時間もかかる
- Batch count:生成何回連続で行うか
- デフォルトでは、seed +1 推移で連続生成する
- Batch size:一回の生成で何枚生成するか
- デフォルトでは、seed +1 推移で連続生成する
- CFG Scale:どれほど prompt の記載に忠実するか
- 大きくするほど、プロンプト通りの画像を生成するようになる
- 大きすぎると絵が崩れることがあるので、8 前後が一般らしい
txt2img - seed

Seed は画像生成に入れる数値で、この数値は生成結果に影響します。
同じ prompt で、同じ設定でも、Seed が違うと全く別の絵が出来上がります。
逆に、設定同じで、Seed も同じなら、大体同じ絵が出来上がります。
なので、画像生成時になんか出たものは自分の予想と違ったら、Seed 値を変えて生成すると描き直してくれます。
txt2img - Script
デフォルトでは None が選択されて、無効になっていますが、他の選択肢にした場合、いつも使っている Prompt が無視されて、こちらを見るようになります。
以下の選択しが存在していますが、
- None
- Prompt metrix
- Prompts from file or textbox
- X/Y/Z plot
- controlnet m2m
今回は Prompts from file or textbox について説明します。

Prompts from file or textbox は一括で複数の prompts を読み込んで、複数の画像を生成する手法です。
テキスト ファイルを読み込ませることもできますし、script の input エリアで、行ごとに画像を生成させることもできます。
- Iterate seed every line:生成された画像の Seed 値が連番になる
- Use same random seed for all lines:すべての画像の Seed 値が統一される
- どれも使わない場合:Seed がランダム値を使う
- 両方入れる場合:Iterate seed every line が優先される
- Negative Prompt はいつもの Negative prompt の内容を読み取る
- 記載例:(画像4枚生成される)
1girl, red hair, 1girl, blue hair, 1girl, yello hair, 1girl, silver hair,
※ 「Generate」ボタンを右クリックして、「generat forever」の選択肢が表示されます。これと併用して連続生成させることができます。「generat forever」は同じく右クリックして停止できます。
最後に
今回で、Stable diffusion の画像生成に使う基本的な設定について勉強しました。基本 prompt に要素を書いて、generat するだけで画像が生成されますが、よりStable diffusionのできることを理解することで、いろんな使い方が思いつくと思います。
ただ、画像の生成はやはり基本的な使い方だけでコントロールできない部分があるので、今後それぞれの課題について学んでいきたいと思います。
コメント