
前回の続きで、今回は Service Health について、一緒に学んでいきたいと思います。
- Azure Monitorの概要
- Azure Monitor:エージェントによるデータ収集
- Azure Service Health
- Azure Monitor:アラート
- Azure Monitor:Log Analytics のソリューション
- Azure Monitor:ログ検索クエリ
- Application insights
- Network Watcher
- Azure Automation
Service Health とは
Azure Service Health では、Azure リソースの正常性についての最新情報を提供する機能となります。
- 提供される情報は以下のものが含まれます:
- サービスに影響するイベント (障害情報など)
- 計画的なメンテナンス
- 可用性に影響する可能性のあるその他の変更
Azure Service Health は 3つのこのたるサービスで構成されています。
- Azure の状態
- Service Health
- Resource Health
Azure の状態
Azure の portal サイトとは別に、マイクロソフトでは Azure サービスの停止に関する情報を提供する Web サイトがあります。
このページでは、すべての Azure リージョンの全 Azure サービスの正常性を確認することができます。
Azure にログインできない場合、こちらのページで サービスの正常性を確認することができます。
Service Health
Service Health は Azure portal サイトにて、確認できるサービス正常性のビューとなります。
追跡される正常性に関するイベント
- サービスに関する問題:ユーザーに今すぐ影響を及ぼす Azure サービスの問題
- 計画メンテナンス:お使いのサービスの可用性に将来影響を及ぼす可能性のある今後のメンテナンス
- 正常性の勧告:ユーザーが注目する必要のある Azure サービスの変化
- 例:Azure の機能が非推奨となることやアップグレードの要件 (サポートされている PHP フレームワークへのアップグレードなど)など
- セキュリティ アドバイザリ:Azure サービスの可用性に影響する可能性があるセキュリティ関連の通知または違反
Service Health の画面:
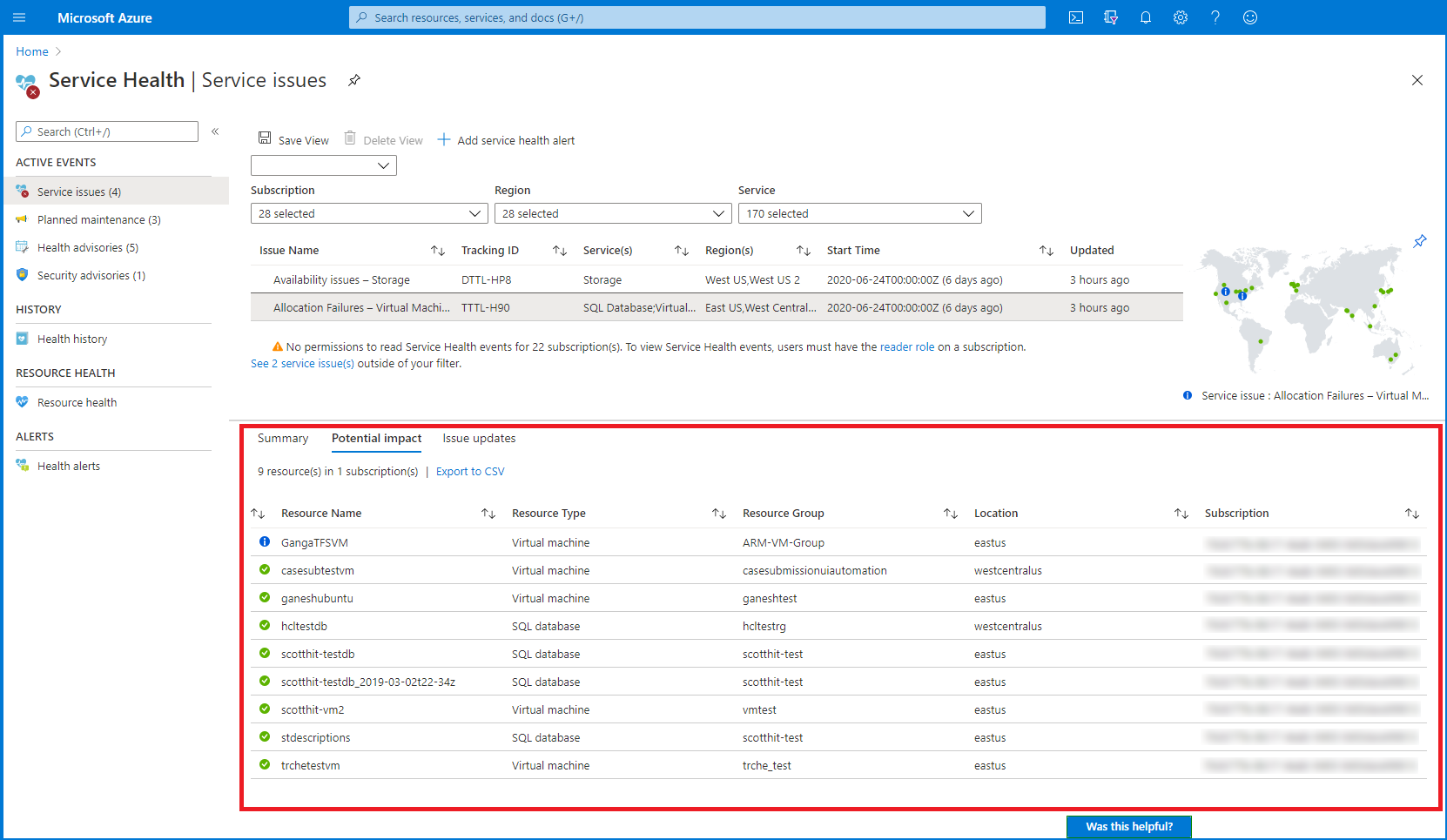
Service Health でできること
- 確認できる情報
- 問題がいつから発生しているか
- どのサービスやリージョンが影響を受けているか
- 問題の影響を受けている可能性のある具体的なリソースの一覧:「可能性のある影響」 (CSVでダウロード可能)
- 問題を解決するための Azure の対策に関する最新の更新情報 (PDF / CSV でダウンロード可能)
- Azure サポート リクエストの起票(問題が解決したのに、リソースが復帰しない場合)
- サービス正常性の地図を Azure ダッシュボードにピン留めする
- サービス正常性のアラートを作成する
- アラート機能を使って、正常性の状態を監視し、イベントが発生した場合、メールで通知させるなどの処理
現在 Azure を使用しているユーザーには、Azure Service Health を利用して Azure のインシデントとメンテナンスに関する最新情報を入手することを強くお勧めします。
場合によっては、「Azure の状態」の方が先に情報が表示される場合がありますが(ユーザー環境のリソース識別処理などで遅延がある)、Azure Service Health を利用することを推進されています。
Resource Health
Resource Health は、Azure サービスの問題によってリソースが利用できなかったすべての時間を示します。
このデータにより、SLA 違反が発生したかどうかを簡単に確認できます。
また、Resource Health は、ユーザーがデプロイした Azure のリソースに対して、正常性チェックが行われています。
※ 正常性の評価方法の詳細については、正常性チェック内容 でリソースの種類と正常性チェックの一覧を参照してください。
正常性の状態
リソースの正常性は以下の状態があります:
- 利用可能:リソースの正常性に影響を与えるイベントが検出されていない
- リソースが過去 24 時間以内に予定外のダウンタイムから回復した場合は、"最近解決された" ことを示す通知が表示される
- 使用不可:
- プラットフォームのイベント:Azure 側のメンテナンスや障害によるもの
- プラットフォーム以外のイベント:ユーザーの操作や、使用量が上限(Azure Cache for Redis への接続数が最大数とか)に達した場合
- Unkonwn:Resource Health がリソースに関する情報を 10 分以上受け取っていない(一般的は、仮想マシンの割り当て解除で発生)
- 低下しています:リソースでパフォーマンス低下が検出されたものの、まだ使用可能
※ プラットフォームのイベントが発生した場合、有効なサポート契約がなくても、MS への問い合わせも可能
プラットフォームのイベントで、使用不可になった場合、使用不可の時点から、最大72時間 Resource Health に、根本原因に関する情報が表示されます。ただ、この情報は現在仮想マシンのみサポートされています。
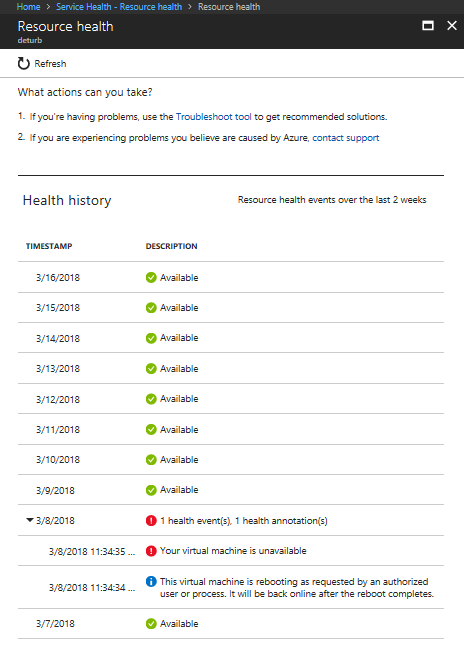
履歴情報
Resource Health の 「正常性の履歴」 セクションで、最大 30 日間の履歴にアクセスできます。
Service Health イベントのアラート作成
サービス正常性の監視として、何かあった際に、メール通知が飛んでくるような運用が望ましいかと思います。
そのためのアラート作成の手順が公式ドキュメントに用意してくれていますので、作成を試したい方は、こちらをご参考していただければと思います。
最後に
今回は Service Health について、一緒に勉強してきました。
割とシンプルな機能なので、理解するのにそこまで難しくないと思います。
ただ、この機能は運用監視の意味では割と大事な部分になっていますので、もし Azure をご利用している場合、ぜひ設定しておきましょう。

コメント